Injecting Numerical Reasoning Skills into Language Models を読んだ
目次
リンク
論文:[2004.04487] Injecting Numerical Reasoning Skills into Language Models
コード:GitHub - ag1988/injecting_numeracy: The accompanying code for "Injecting Numerical Reasoning Skills into Language Models" (Mor Geva*, Ankit Gupta* and Jonathan Berant, ACL 2020).
比較手法のMTMSN:GitHub - huminghao16/MTMSN: A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning
比較手法のNABERT+:GitHub - raylin1000/drop-bert: NABERT model for solving the DROP dataset
評価用データセットDROPの論文:[1903.00161] DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
概要
- LanguageModelに数値推論を注入する汎用モデル(GenBERT)と、それをpre-trainingするための学習用データを生成するためのフレームワークを提案
- 既存の数値推論を評価用データセット(NRoT; Numerical Reasoning over Text)にてSOTAのモデルと同程度の性能を発揮することを示した
数値推論の例

数値推論の質問は複数種類あり、Passage(Contextともいう)やQuestionから該当する文字列を抽出すれば良いspanや、数値計算が必要なnumberがある。他にも複数のフレーズの抽出が必要なspansや、日付の計算が必要なdateがある。
提案手法の内容
複数のheadを用いて回答を行う。headの種類は3つ。
- answer type head: 回答方法を決定する(context span, question span, decodeのマルチクラス分類)
- two span-extraction heads: ContextかQuestionから回答を抽出する(NER)
- generative head: 回答を生成する

モデルのLossには以下を用いる。*1

EncoderのBERTとの差分
Digit Tokenization(DT)
数値計算用に数値を1文字ずつのwordpieceにする

Random Shift(RS)
“1086.1 - 2.54 + 343.8”の様な短いテキストを学習に用いるため、数値が先頭に来る場合に数値推論を行うようにオーバーフィットしてしまう。これを避けるためにposition IDをランダムにする*2。
学習・推論の全体像
pre-train済みのLanguageModel(BERT)をNumerical Data(ND)とTextual Data(TD)を用いて追加pre-trainする。
数値推論を行う場合はspan extraction headsとgenerative headの両方をfine-tuningする。 SQuADの様なテキストのみの質疑応答の場合はspan extraction headsのみを用いる。
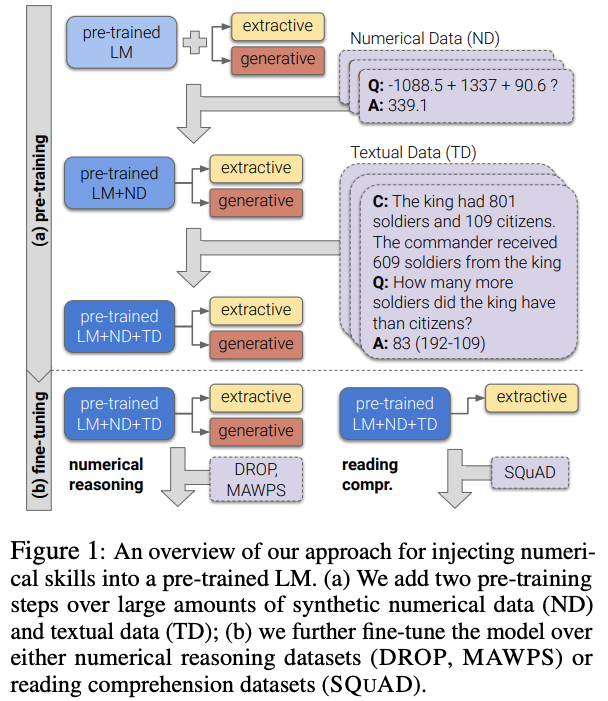
pre-trainingの方法
pre-training用のNumerical Data (ND)の生成
テンプレートを用いて数値演算のテキストを生成する。テンプレートはTable 2を参照。



数値実験
ND・TDによる追加pre-trainの効果
各モデルをDROPのデータでfine-tuningした結果で比較。追加pre-trainなしだとEMが46.1と低い。ND+TDで追加pre-trainすることでSOTAのMTMSNと同程度の性能になる*6。
Table 4からLM(追加pre-train時のMLM)やRandom Shiftも効果があることが分かる。

Digit Tokenizationの効果
pre-trainingのstep数毎のaccuracy。Digit Tokenizationが無い場合のみAccが低く、精度改善に寄与している事がわかる。

言語理解能力を失っていないかの確認
数値推論が不要な質疑応答(SQuAD)でfine-tuningして評価を行う。
GENBERTは数値推論を行いつつ、言語理解能力も失わずBERTと同程度であることが分かる。


補足
pre-training、fine-tuning時のパラメータ

DROPの質問種別毎の精度
数値計算(number)では予想通りMTMSNより精度が高い。
spanでもMTMSNより精度が高いが、これは内部的に数値計算を実行した上でspanを回答できるためだと考えられる。
spansは答えが連続しないフレーズのリストの質問だが、MTMSNはGENBERTを大幅に上回る。これはMTMSNはspans用の専用ヘッドを持っているが、GENBERTは標準的なReasoning Comprehension用のヘッドしか持たないためである。

数値理解能力の検証
数学の単語問題(MWP)データセットのコレクション(MAWPS)を用いて評価する。fine-tuningは行わずにzero-shotで評価を行う。
GENBERT+ND+TDは、GENBERT(BERTのママ)と比較して劇的に性能を向上させる。GENBERT+NDはGENBERT+TDよりもはるかに優れた性能を発揮し、コンテキストが短い場合のNDの有用性を示している。
MTMSNはGENBERT+ND+TDを上回る。MTMSNは足し算と引き算に特化したアーキテクチャを使用しており、モデル外で計算が行われる場合に適している。

次に、演算式の項の数で性能を比較する(図5)。図からすべてのモデルがより複雑な問題に一般化するのに苦労しており、項が4以上になると完全に失敗している。GENBERT+ND+TDの2項と3項の間の性能低下は、GENBERT+NDとGENBERT+TDよりも有意に小さい。このことはNDとTDの両方がロバスト性を向上させるのに有効であることを示唆している。

Error analysis
DROPのdevセットのGENBERT+ND+TDの誤答を分析する。モデルがサポートしていないマルチスパンの解答を持つ問題を除外した上で、GENBERT+ND+TDが誤答したものを100例のランダムサンプリングし、誤答の種類を手動で分類した。具体的な例は以下のTable 11を参照。

ほぼ半数のケース(43%)では、事前学習課題(ソートなど)でカバーされていないか、数値的ではない推論スキルを必要としているものだった。もう一つの一般的なケース(23%)は抽出したスパンが長すぎたり、予測値とgold answerと数字が部分的に一致する場合であった。これらのエラーの多くは、事前学習課題を拡張して追加の数値スキルやより大きな数値範囲をカバーすることで対処できると思われる。
*1:このLossだとspan extractionで抽出される文字列をdecoderで生成することも可能だが、span extractionで解くべき問題をdecoderで解いた場合にどういう計算になるのかは不明。またdecoderで解くべき問題の時に正しいspanを選択する確率がどうなるのか不明。
*2:Random Shiftで設定する値はwhen the input length n1 + n2 + 3 < 512, we shift all position IDs by a random integer in \(0, 1, . . . , 512 − \(n1 + n2 + 3\)
*3:Hosseini et al. 2014. Learning to Solve Arithmetic Word Problems with Verb Categorization - ACL Anthology
*4:データ生成は品詞に抽象化したテンプレートに単語を当てはめるような手法を用いている。Figure 3を参照。
*5:Kirkpatrick, 2017 [1612.00796] Overcoming catastrophic forgetting in neural networks
*6:SOTAはBERT-largeをベースにしたMTMSNだが、比較のために今回はBERT-baseをベースにしたMTMSNを比較対象としている