SimCSE: Simple Contrastive Learning of Sentence Embeddings
目次
リンク
論文:[2104.08821] SimCSE: Simple Contrastive Learning of Sentence Embeddings
コード:GitHub - princeton-nlp/SimCSE: EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
Sentence-TransformersのSimCSE:
SimCSE — Sentence-Transformers documentation
概要
ContrastiveLossを用いてSentenceEmbeddingsを行う。Unsupervisedな方法と、Supervisedの方法の2つを提案。
Unsupervised SimCSEでは、dropoutのノイズによるData Argumentationを用いて学習を行う。STSデータセットでBERT,RoBERTaなどと比較して高い精度が確認された。
Supervised SimCSEでは、NLIデータセットのentailmentとcontradictionのデータのみを用いて学習を行う。SentenceBERTなどと比較して高い精度が得られた。
提案手法
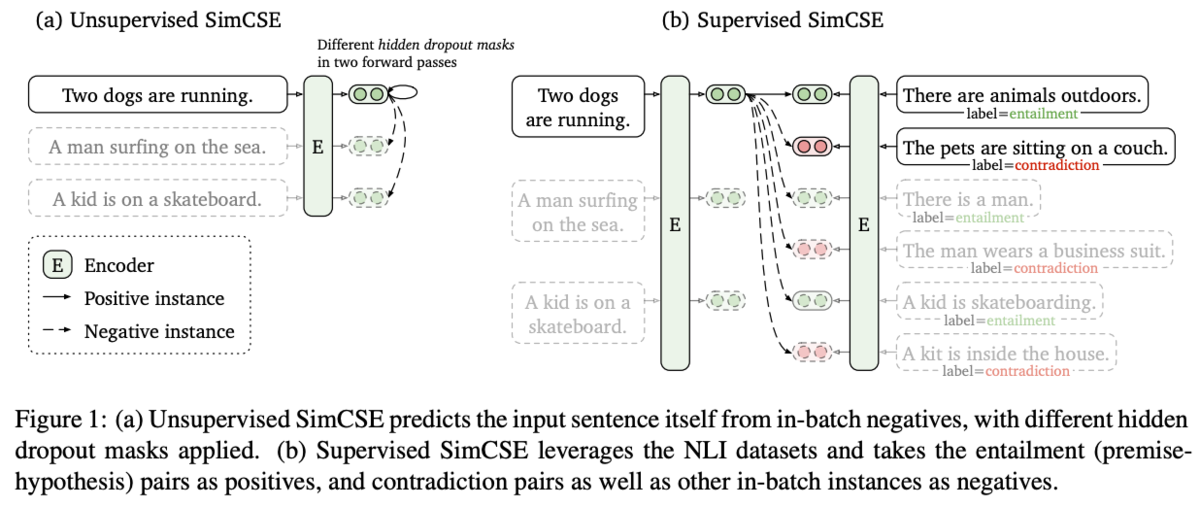
Unsupervised SimCSE
隠れ層のdropoutをノイズと考え、data augmentationとして用いる。
正例には1つのSentenceに対してdropoutを適用したencodeを2度行い、異なるdropoutが行われた2つの出力を正例とする。dropoutはTransformerと同じで全結合層とアテンション確率のみで、新たなdropoutは追加しない。
負例はミニバッチ内で別のSentenceをサンプリングしたものを用いる。
LossにはContrastiveLossを用いる。
Supervised SimCSE
NLI(natural language inference) データセットを用いて学習を行う。NLIのデータは2つのSentenceに対して、entailment, neutral, contradictionの3種類のラベルのいずれかが付与されている。
NLIのデータセットにはQQP, Flickr30k, ParaNMT, SNLI, MNLIなどがある。
正例にはNLIのentailmentのラベルのデータを用いる。
負例にはcontradictionのラベルのデータを用いる。
neutralのラベルのデータは学習に用いない。
LossにはContrastiveLossを用いる。
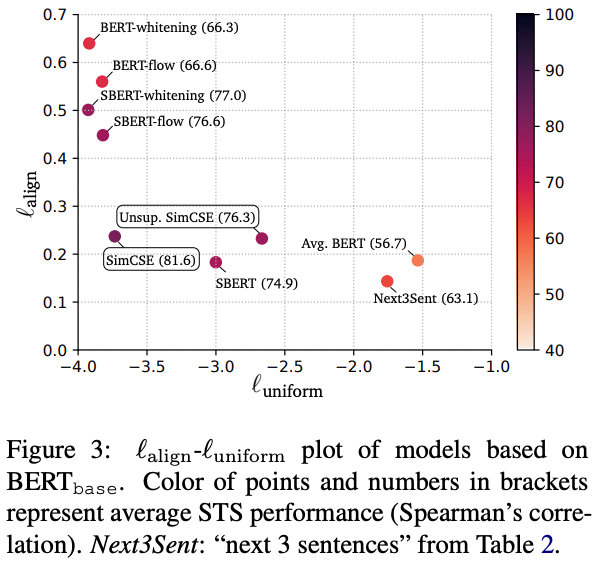
評価結果
他手法との比較
STSデータセット*1を用いて比較を行う。
STSのデータには2つのSentenceのペアに対して類似度が付与されている。例えば、「A young child is riding a horse.」と「A child is riding a horse.」のペアの類似度は4.75で、「A man is crying.」と「A woman is dancing.」のペアの類似度は0.60といったデータになっている。類似度は[0, 5]の間の値になる。
各手法でencodeした出力のCosine類似度と、STSの類似度の相関係数で評価する。
Unsupervised modelとSupervised model同士で比較を行う。
Unsupervised modelの比較対象にはpretrainのみでfinetuneを行っていないBERTでencodeする方法を含める。BERT単体はSupervised modelの比較対象には含めない。
Supervised modelの比較対象にはNLIデータセットでfinetuneしたSentenceBERTを含める。SentenceBERTはUnsupervised modelの比較対象には含めない。
手法名の後ろに-flow, -whiteningが付いているものはencode結果を後処理で変えたもので、類似度の分布が変わっている。
Unsupervised model、Supervised modelの両方で、提案手法のSimCSEが最も良い結果になっている。
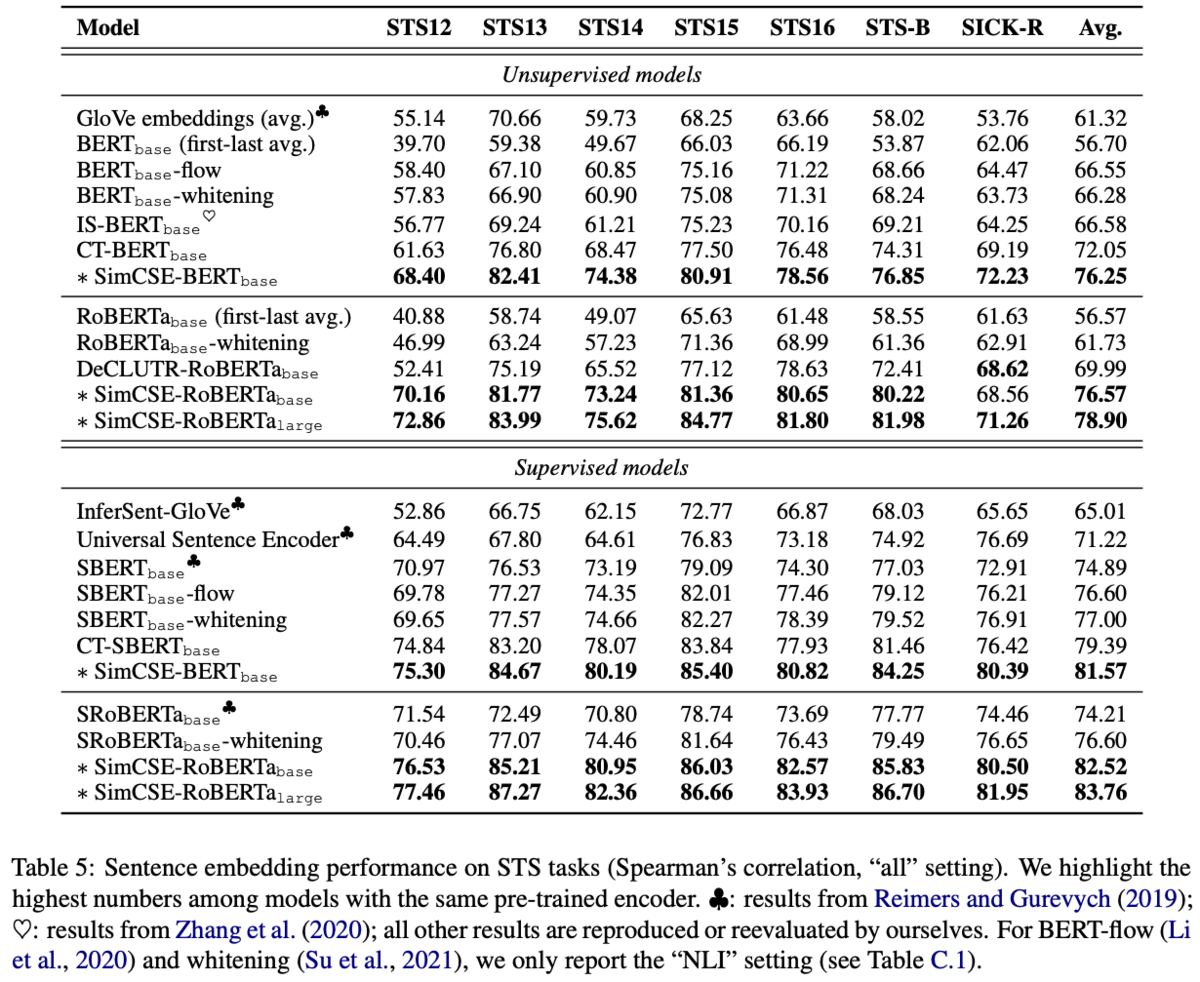
Alignment and uniformity
学習によって得られたベクトルを評価するために、Wang and Isola (2020)が提案したalignmentとuniformityの2つの指標を用いる。
alignmentは正例となる2つのSentenceの距離が近いほど小さい値になる。

uniformityは超球面上にベクトルが一様に分布しているかどうかを計測するもので、値が小さいほどベクトルが一様に分布していることになる。

この2つの指標を用いて、SimCSEがencodeで出力するベクトルの内容を評価する。
Figure 2 は異なるdata argumentationのUnsupervised modelの学習時に10ステップごとのalignmentとuniformityの推移を表したものである。uniformityはどの手法でargumentationを行っても学習とともに小さくなり、Contrastive Learningを行うことでベクトルの均一性が向上することがわかる。一方で正例の文ペアのalignmentはdropout(Unsup. SimCSE)やDelete one wordではalignmentを保っているが、それ以外では悪化してしまっている。Delete one wordはUnsup. SimCSEよりもalignmentを下げることができているが、uniformityの下げ幅は小さくなってしまう。後述のTable 1の比較結果を見るとWord deletionの文類似度推定(STS-B)の精度は低いので、uniformityが文類似度推定では重要と考えられる。
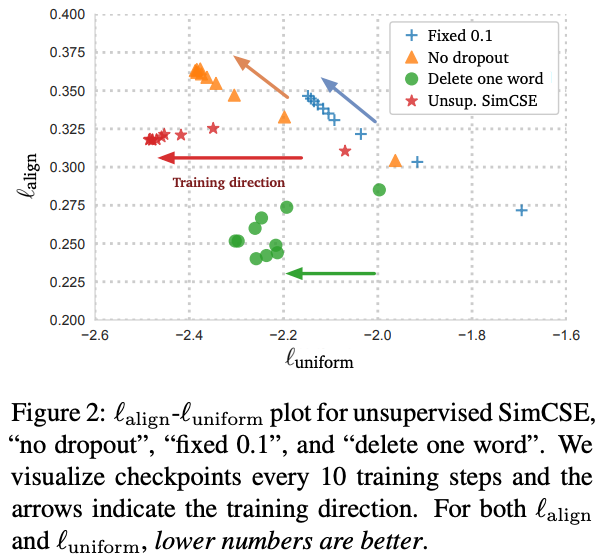
Figure 3はUnsupervised modelとSupervised modelのalignment、uniformity、STSの文類似度推定でのパフォーマンスをプロットしたものになっている。
- 一般的に、alignmentとuniformityの両方が優れているモデルはSTSで良い性能を達成しており、Wang and Isola (2020)の結果と一致する(SimCSE, SBERT, Unsup. SimCSEあたり?)
- pretrainされたモデルはalignmentは良いが、uniformityが悪く、encodeされたベクトルは均一でなくどこかに集中しやすい(Avg. BERT, Next3Sent)
- -flowや-whiteningのような後処理法はuniformityを大きく改善するが、alignmentは悪化する(BERT-whitening, BERT-flow, SBERT-whitening, SBERT-flow)
- Unsupervised SimCSEは、良好なalignmentを維持しながらpretrainされた埋め込みのuniformityを効果的に改善する
- SupervisedSimCSEに教師ありのデータを組み込む(Unsup. SimCSEをSup. SImCSEでfinetuneするということか?)と、alignmentがさらに改善される(論文ではalignmentが改善と書いてあるが、図ではuniformityが改善しているように見える)
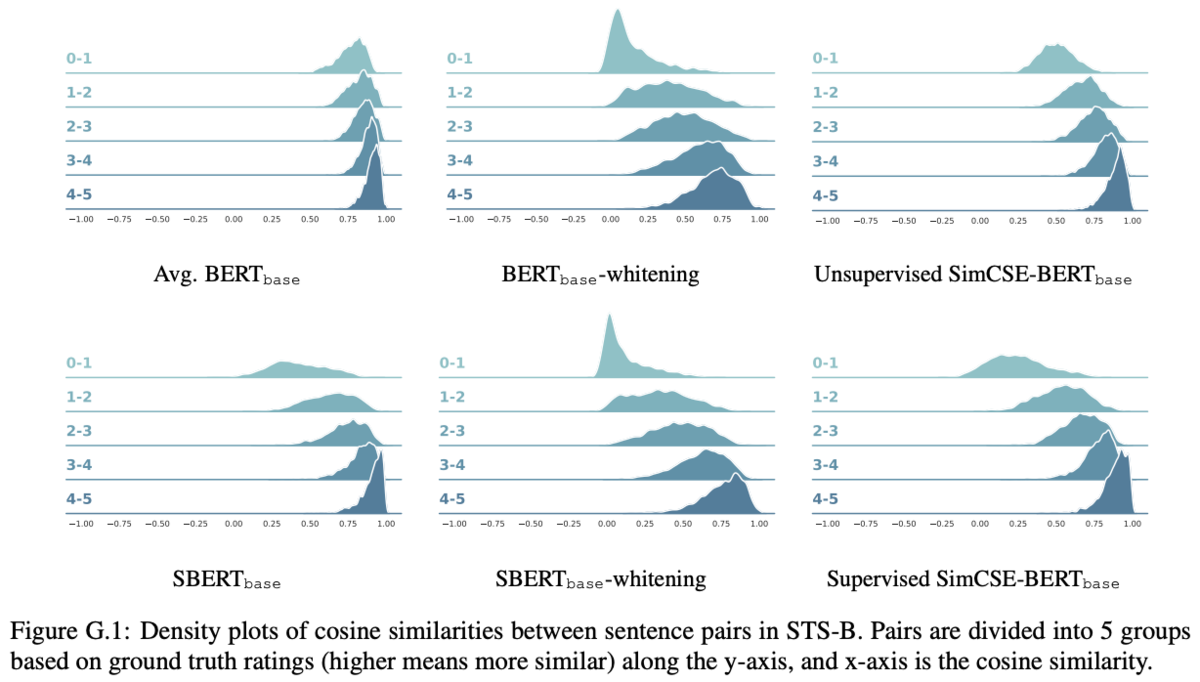
また、Figure G.1 ではSTS-Bの文類似度の値を1ずつに刻んで縦に並べ、モデルが推定した文類似度を横軸にとったものである。
SimCSEは、BERTやSentenceBERTよりも分散した分布になっている。一方、whiteningしたものよりは分布の分散は低いが、Table 5やFigure 3を見るとwhiteningされたベクトルの性能は低く、SimCSEの方がalignmentとuniformityのバランスが取れているといえる。
Unsupervised SimeCSEの検証
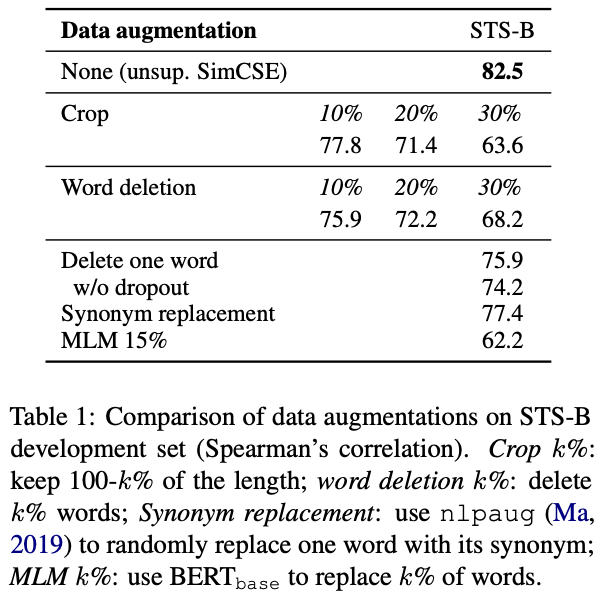
data augmentationの手法としての比較
Unsupervisedな学習でdropoutをノイズとして利用する方法は、data augmentationの手法の1つ。
一般的なdata augmentationの手法(CropやWord deletionなど)と比較しても提案手法のUnsupervised SimCSEが最も良い結果。
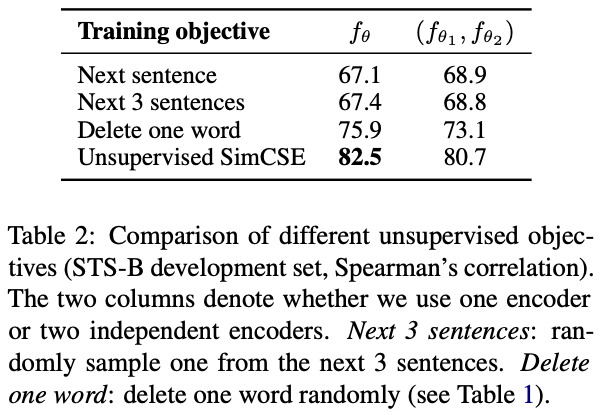
また、提案手法では1つのSentenceに対してdropoutを適用したencodeを2回行うことで正例を作成しているが、文章中の次の文を正例とする方法(Next Sentence)や、文章中で文に続く3つ文からランダムで選択した1つを正例とする方法(Next 3 Sentence)も挙げられる。これらで比較してもdropoutを用いたUnsupervised SimCSEの精度が最も高い。
文のペアのencodeを行う際に1つのネットワークを用いるか、異なる2つのネットワークを用いるかの比較も行っている(その場合、学習後に片方のネットワークは捨てる?)。Unsupervised SimCSEでは1つのネットワークを用いてencodeを行うほうが精度が高い。
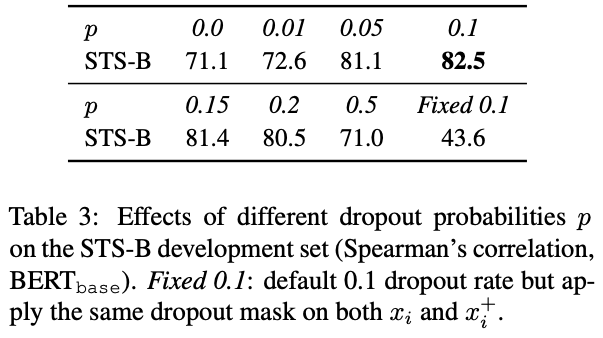
dropout確率による精度の変化
Unsupervised SimCSEを行う際のdropout確率 p を変化させて精度を評価したところ、dropout確率が0.1のときが最も精度が高かった。
Fixed 0.1は正例作成時に2回encode行う際のdropoutのマスクを同じにした場合の結果。同一Sentenceの異なるdropoutの出力を正例にすることで学習がうまくいくということだったが、Fixed 0.1は同じベクトルをContrastive Learningで学習しているだけなので、何も学習していない気もする。
Supervised SimeCSEの検証
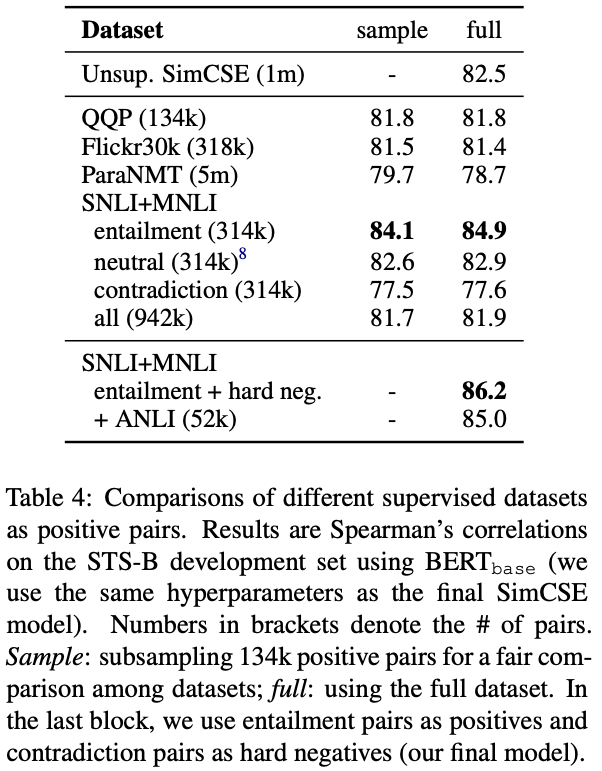
Supervised SimCSEの学習に用いるデータセットによる精度の違い
NLIデータセットを用いてSupervised SimCSEの学習を行い、STS-Bデータセットで検証を行う。
提案手法はSNLI+MNLI (entailment + hard negative)である。
各データセットのデータ数は異なるので、sampleはデータ数が最も少ないQQPの134k件で学習した結果の比較。学習で用いるデータ数をあわせると、SNLIとMNLIのentailmentのデータを正例として学習した場合のSupervised SimCSEの精度が最も良い。この時、学習に用いるのはentailmentのデータのみを正例とし、neutral, contradictionは用いない。同様にneutral, cotradictionの時も該当のラベルのみを正例とし、負例は存在しない。allも正例のみで、負例は無い状態で学習したものである。
提案手法であるSNLI+MNLI (entailment + hard negative)はデータ数を揃えられないのでsampleの結果はないが、データ全件を学習に利用するfullでは提案手法のSNLI+MNLI (entailment + hard negative)が最も精度が良い。
ANLIもNLIのデータセットの1つだが、SNLI+MNLIにANLIのデータセットを追加すると精度が下がってしまう。
ablation study
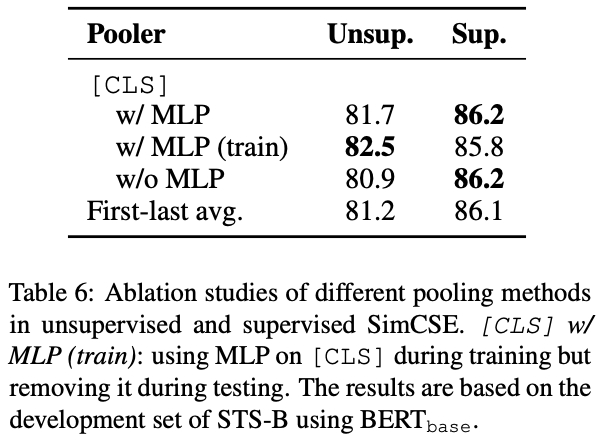
Pooling層による精度の違い
pooling方法として4種類試す。
- w/MLP : [CLS] にMLPを結合したもの
- w/MLP(train) : [CLS] に学習時はMLPを結合して行うが、推論時はMLPを削除したもの
- w/o MLP : [CLS]の出力をそのまま利用したもの
- First-last avg : 第1層と最終層のembeddingの平均(SentenceBERTで利用されている?)
論文にはUnsupervised SimCSEはw/MLP(train)が良く、Supervised SimCSEではw/MLPが良いと記載されている。
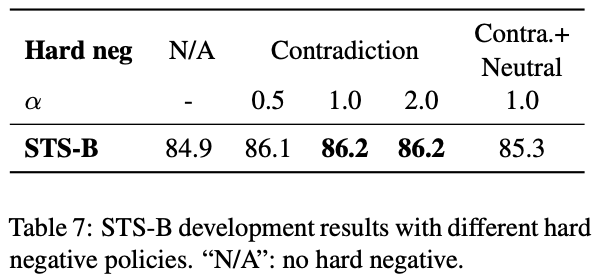
Supervised SimCSE学習時のhard negativeの効果
Supervised SimCSEの学習時のhard negativeの重みをαで調整できるようにし、hard negativeの効果を評価する。
hard negativeを含めないN/Aのケースが最も低く、Contradictionの重みを1にした時の精度が最も高い。hard negativeにContradictionだけでなくNeutralを混ぜた場合は、Contradictionのみをhard negativeにした時よりも精度が下がってしまう。

定性評価
Supervised SimCSEとSentenceBERTの比較。

*1:STSデータセットについてはSTSbenchmark - stswiki を参照