EX3: Explainable Attribute-aware Item-set Recommendations
論文:
https://dl.acm.org/doi/10.1145/3460231.3474240
論文(Amazon scienceの方):EX³: Explainable attribute-aware item-set recommendations - Amazon Science
手法についてはWantedlyの記事が詳しいので、こちらを読んだほうが良い。pdfには載ってない図も掲載されていてわかりやすい。
www.wantedly.com
気になる点の幾つかがWantedlyの記事には掲載されてなかったので、その部分だけ読んだ。
用語
- pivot item : レコメンドの元になるアイテム。query itemやseed itemと呼ばれたりするやつ。
: co-purchase
: co-view
: purchase-after-view
実験
オフラインテスト
Amazon.comの7つのサブドメインのデータを用いてオフライン評価を実施。オフラインテストについては、論文中にAmazon.comと明記されている。

Top-N Recommendation Performance (Expect-Step)
提案手法のExpect-stepが既存手法と同程度のrelevanceを出力できるかの確認。提案手法ではこの後にExplain-stepがあるのが、既存手法と比較するためにExpect-stepで評価する。
検証では提案手法のEX³が最もよい。
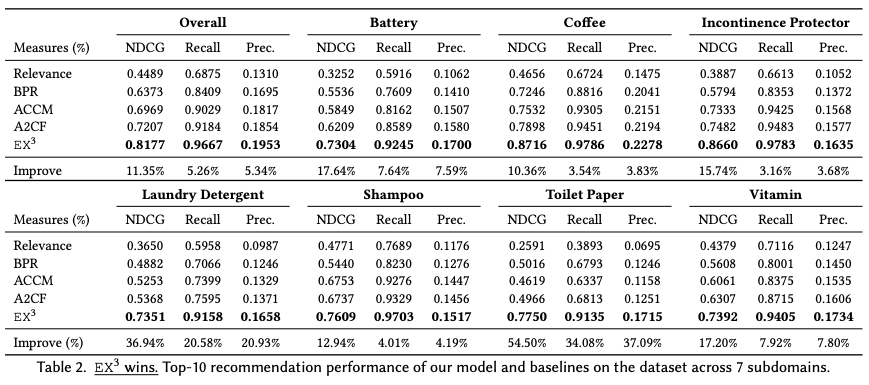
比較手法
Model Robustness to Missing Attributes
商品属性の欠損値の影響を評価する。評価時のテストセットの属性にランダムで欠損値を 10%, 20% と増やして評価する。比較対象は提案手法と、提案手法(Figure 3. の青線)からAttention機構を取り除いたもの(Figure 3. の赤線)。

*1:Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. In UAI.
*2:Shaoyun Shi, Min Zhang, Yiqun Liu, and Shaoping Ma. 2018. Attention-based Adaptive Model to Unify Warm and Cold Starts Recommendation. CIKM (2018).
*3:Tong Chen, Hongzhi Yin, Guanhua Ye, Zi Huang, Yang Wang, and Meng Wang. 2020. Try This Instead: Personalized and Interpretable Substitute Recommendation. SIGIR.
SimCSE: Simple Contrastive Learning of Sentence Embeddings
目次
リンク
論文:[2104.08821] SimCSE: Simple Contrastive Learning of Sentence Embeddings
コード:GitHub - princeton-nlp/SimCSE: EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
Sentence-TransformersのSimCSE:
SimCSE — Sentence-Transformers documentation
概要
ContrastiveLossを用いてSentenceEmbeddingsを行う。Unsupervisedな方法と、Supervisedの方法の2つを提案。
Unsupervised SimCSEでは、dropoutのノイズによるData Argumentationを用いて学習を行う。STSデータセットでBERT,RoBERTaなどと比較して高い精度が確認された。
Supervised SimCSEでは、NLIデータセットのentailmentとcontradictionのデータのみを用いて学習を行う。SentenceBERTなどと比較して高い精度が得られた。
提案手法
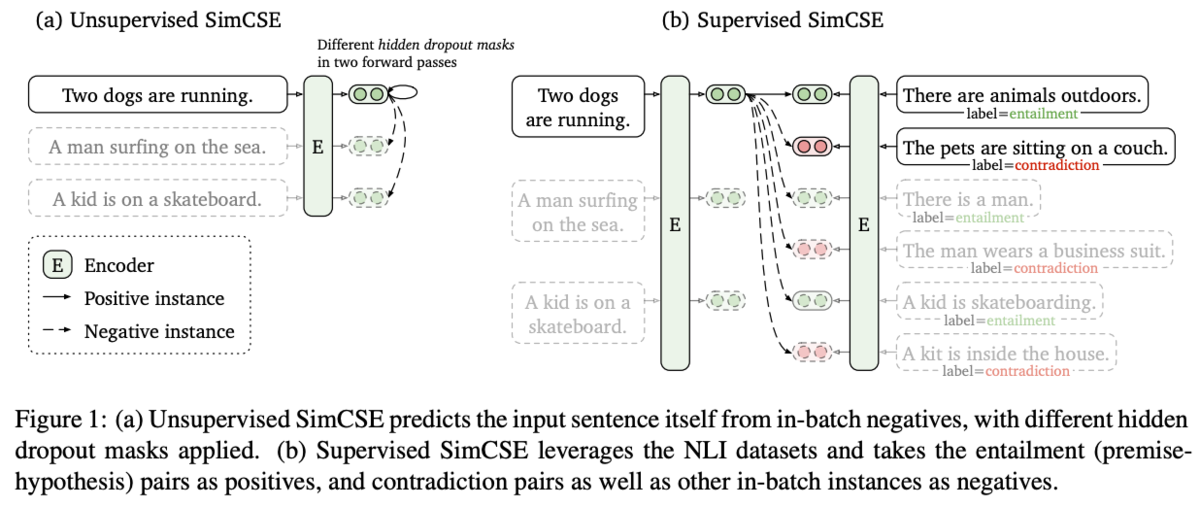
Unsupervised SimCSE
隠れ層のdropoutをノイズと考え、data augmentationとして用いる。
正例には1つのSentenceに対してdropoutを適用したencodeを2度行い、異なるdropoutが行われた2つの出力を正例とする。dropoutはTransformerと同じで全結合層とアテンション確率のみで、新たなdropoutは追加しない。
負例はミニバッチ内で別のSentenceをサンプリングしたものを用いる。
LossにはContrastiveLossを用いる。
Supervised SimCSE
NLI(natural language inference) データセットを用いて学習を行う。NLIのデータは2つのSentenceに対して、entailment, neutral, contradictionの3種類のラベルのいずれかが付与されている。
NLIのデータセットにはQQP, Flickr30k, ParaNMT, SNLI, MNLIなどがある。
正例にはNLIのentailmentのラベルのデータを用いる。
負例にはcontradictionのラベルのデータを用いる。
neutralのラベルのデータは学習に用いない。
LossにはContrastiveLossを用いる。
評価結果
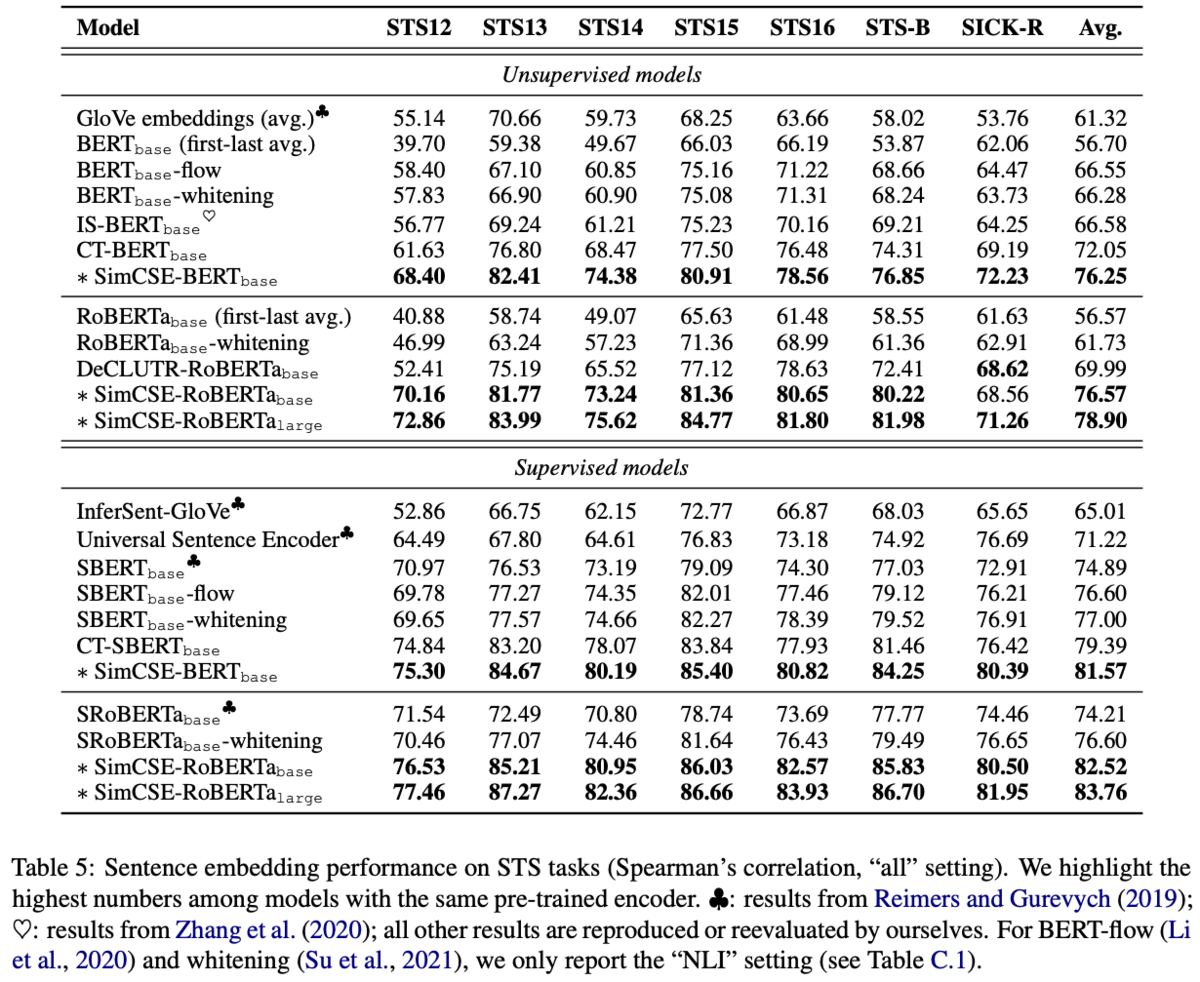
他手法との比較
STSデータセット*1を用いて比較を行う。
STSのデータには2つのSentenceのペアに対して類似度が付与されている。例えば、「A young child is riding a horse.」と「A child is riding a horse.」のペアの類似度は4.75で、「A man is crying.」と「A woman is dancing.」のペアの類似度は0.60といったデータになっている。類似度は[0, 5]の間の値になる。
各手法でencodeした出力のCosine類似度と、STSの類似度の相関係数で評価する。
Unsupervised modelとSupervised model同士で比較を行う。
Unsupervised modelの比較対象にはpretrainのみでfinetuneを行っていないBERTでencodeする方法を含める。BERT単体はSupervised modelの比較対象には含めない。
Supervised modelの比較対象にはNLIデータセットでfinetuneしたSentenceBERTを含める。SentenceBERTはUnsupervised modelの比較対象には含めない。
手法名の後ろに-flow, -whiteningが付いているものはencode結果を後処理で変えたもので、類似度の分布が変わっている。
Unsupervised model、Supervised modelの両方で、提案手法のSimCSEが最も良い結果になっている。
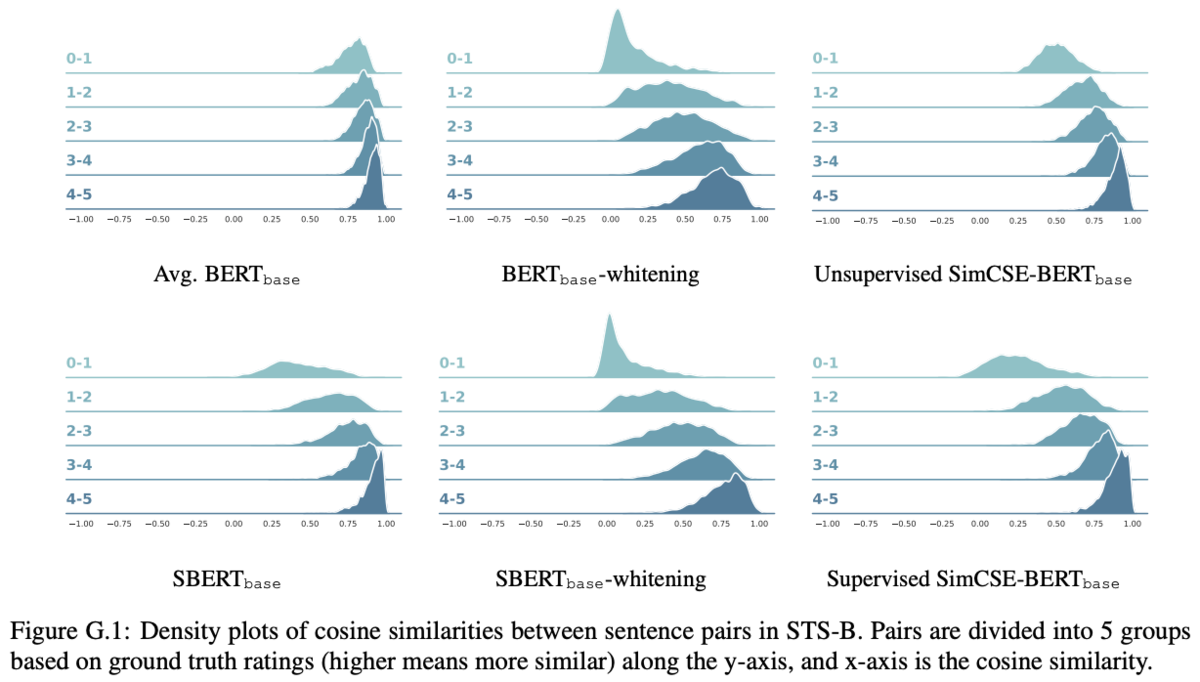
Alignment and uniformity
学習によって得られたベクトルを評価するために、Wang and Isola (2020)が提案したalignmentとuniformityの2つの指標を用いる。
alignmentは正例となる2つのSentenceの距離が近いほど小さい値になる。

uniformityは超球面上にベクトルが一様に分布しているかどうかを計測するもので、値が小さいほどベクトルが一様に分布していることになる。

この2つの指標を用いて、SimCSEがencodeで出力するベクトルの内容を評価する。
Figure 2 は異なるdata argumentationのUnsupervised modelの学習時に10ステップごとのalignmentとuniformityの推移を表したものである。uniformityはどの手法でargumentationを行っても学習とともに小さくなり、Contrastive Learningを行うことでベクトルの均一性が向上することがわかる。一方で正例の文ペアのalignmentはdropout(Unsup. SimCSE)やDelete one wordではalignmentを保っているが、それ以外では悪化してしまっている。Delete one wordはUnsup. SimCSEよりもalignmentを下げることができているが、uniformityの下げ幅は小さくなってしまう。後述のTable 1の比較結果を見るとWord deletionの文類似度推定(STS-B)の精度は低いので、uniformityが文類似度推定では重要と考えられる。
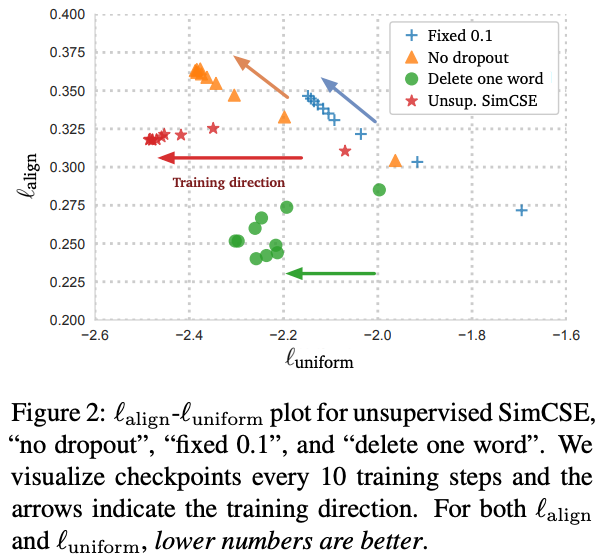
Figure 3はUnsupervised modelとSupervised modelのalignment、uniformity、STSの文類似度推定でのパフォーマンスをプロットしたものになっている。
- 一般的に、alignmentとuniformityの両方が優れているモデルはSTSで良い性能を達成しており、Wang and Isola (2020)の結果と一致する(SimCSE, SBERT, Unsup. SimCSEあたり?)
- pretrainされたモデルはalignmentは良いが、uniformityが悪く、encodeされたベクトルは均一でなくどこかに集中しやすい(Avg. BERT, Next3Sent)
- -flowや-whiteningのような後処理法はuniformityを大きく改善するが、alignmentは悪化する(BERT-whitening, BERT-flow, SBERT-whitening, SBERT-flow)
- Unsupervised SimCSEは、良好なalignmentを維持しながらpretrainされた埋め込みのuniformityを効果的に改善する
- SupervisedSimCSEに教師ありのデータを組み込む(Unsup. SimCSEをSup. SImCSEでfinetuneするということか?)と、alignmentがさらに改善される(論文ではalignmentが改善と書いてあるが、図ではuniformityが改善しているように見える)
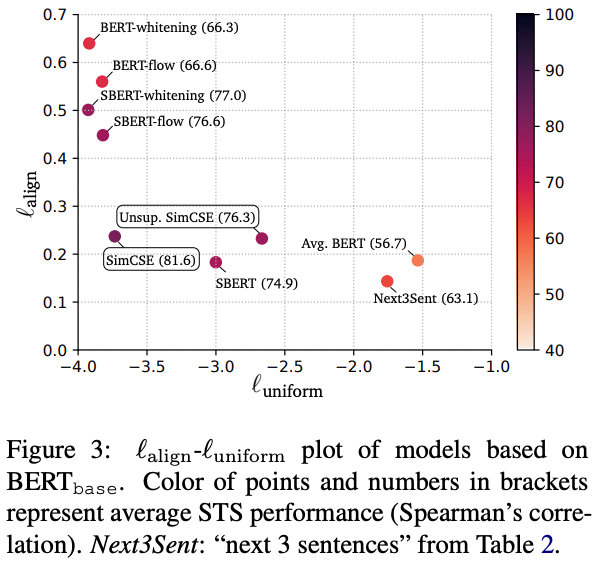
また、Figure G.1 ではSTS-Bの文類似度の値を1ずつに刻んで縦に並べ、モデルが推定した文類似度を横軸にとったものである。
SimCSEは、BERTやSentenceBERTよりも分散した分布になっている。一方、whiteningしたものよりは分布の分散は低いが、Table 5やFigure 3を見るとwhiteningされたベクトルの性能は低く、SimCSEの方がalignmentとuniformityのバランスが取れているといえる。
Unsupervised SimeCSEの検証
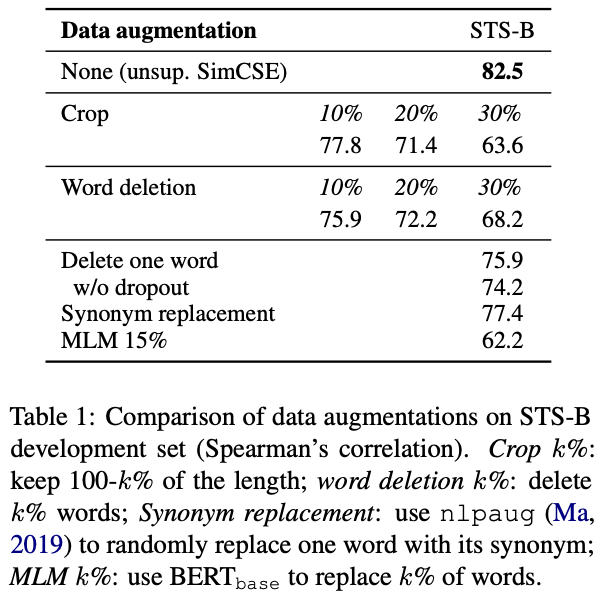
data augmentationの手法としての比較
Unsupervisedな学習でdropoutをノイズとして利用する方法は、data augmentationの手法の1つ。
一般的なdata augmentationの手法(CropやWord deletionなど)と比較しても提案手法のUnsupervised SimCSEが最も良い結果。
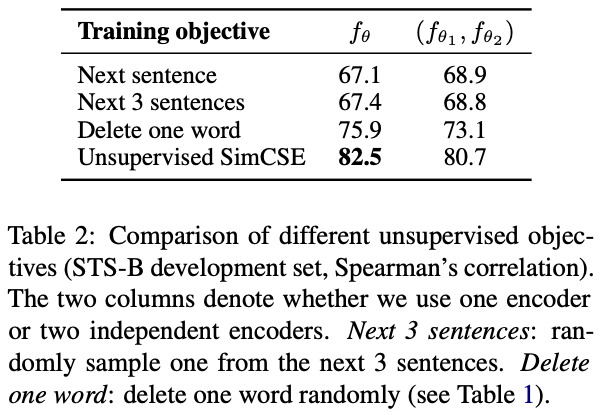
また、提案手法では1つのSentenceに対してdropoutを適用したencodeを2回行うことで正例を作成しているが、文章中の次の文を正例とする方法(Next Sentence)や、文章中で文に続く3つ文からランダムで選択した1つを正例とする方法(Next 3 Sentence)も挙げられる。これらで比較してもdropoutを用いたUnsupervised SimCSEの精度が最も高い。
文のペアのencodeを行う際に1つのネットワークを用いるか、異なる2つのネットワークを用いるかの比較も行っている(その場合、学習後に片方のネットワークは捨てる?)。Unsupervised SimCSEでは1つのネットワークを用いてencodeを行うほうが精度が高い。
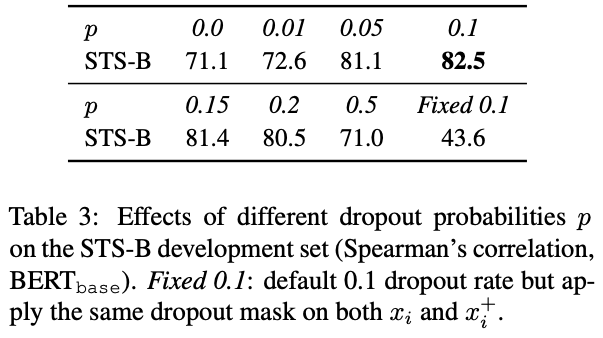
dropout確率による精度の変化
Unsupervised SimCSEを行う際のdropout確率 p を変化させて精度を評価したところ、dropout確率が0.1のときが最も精度が高かった。
Fixed 0.1は正例作成時に2回encode行う際のdropoutのマスクを同じにした場合の結果。同一Sentenceの異なるdropoutの出力を正例にすることで学習がうまくいくということだったが、Fixed 0.1は同じベクトルをContrastive Learningで学習しているだけなので、何も学習していない気もする。
Supervised SimeCSEの検証
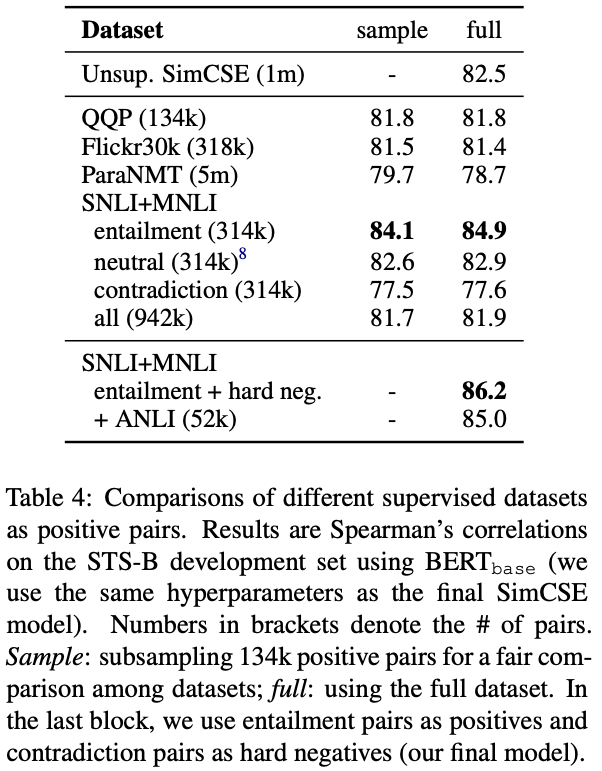
Supervised SimCSEの学習に用いるデータセットによる精度の違い
NLIデータセットを用いてSupervised SimCSEの学習を行い、STS-Bデータセットで検証を行う。
提案手法はSNLI+MNLI (entailment + hard negative)である。
各データセットのデータ数は異なるので、sampleはデータ数が最も少ないQQPの134k件で学習した結果の比較。学習で用いるデータ数をあわせると、SNLIとMNLIのentailmentのデータを正例として学習した場合のSupervised SimCSEの精度が最も良い。この時、学習に用いるのはentailmentのデータのみを正例とし、neutral, contradictionは用いない。同様にneutral, cotradictionの時も該当のラベルのみを正例とし、負例は存在しない。allも正例のみで、負例は無い状態で学習したものである。
提案手法であるSNLI+MNLI (entailment + hard negative)はデータ数を揃えられないのでsampleの結果はないが、データ全件を学習に利用するfullでは提案手法のSNLI+MNLI (entailment + hard negative)が最も精度が良い。
ANLIもNLIのデータセットの1つだが、SNLI+MNLIにANLIのデータセットを追加すると精度が下がってしまう。
ablation study
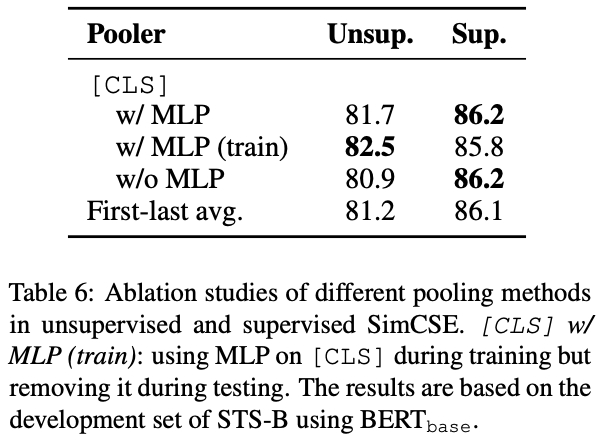
Pooling層による精度の違い
pooling方法として4種類試す。
- w/MLP : [CLS] にMLPを結合したもの
- w/MLP(train) : [CLS] に学習時はMLPを結合して行うが、推論時はMLPを削除したもの
- w/o MLP : [CLS]の出力をそのまま利用したもの
- First-last avg : 第1層と最終層のembeddingの平均(SentenceBERTで利用されている?)
論文にはUnsupervised SimCSEはw/MLP(train)が良く、Supervised SimCSEではw/MLPが良いと記載されている。
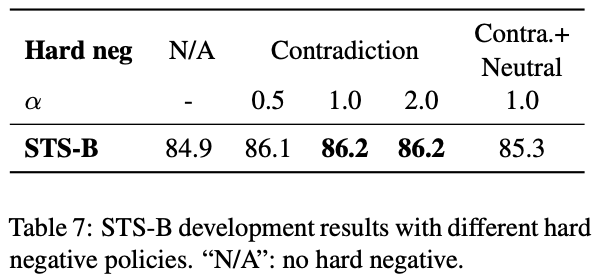
Supervised SimCSE学習時のhard negativeの効果
Supervised SimCSEの学習時のhard negativeの重みをαで調整できるようにし、hard negativeの効果を評価する。
hard negativeを含めないN/Aのケースが最も低く、Contradictionの重みを1にした時の精度が最も高い。hard negativeにContradictionだけでなくNeutralを混ぜた場合は、Contradictionのみをhard negativeにした時よりも精度が下がってしまう。

定性評価
Supervised SimCSEとSentenceBERTの比較。

*1:STSデータセットについてはSTSbenchmark - stswiki を参照
Injecting Numerical Reasoning Skills into Language Models を読んだ
目次
リンク
論文:[2004.04487] Injecting Numerical Reasoning Skills into Language Models
コード:GitHub - ag1988/injecting_numeracy: The accompanying code for "Injecting Numerical Reasoning Skills into Language Models" (Mor Geva*, Ankit Gupta* and Jonathan Berant, ACL 2020).
比較手法のMTMSN:GitHub - huminghao16/MTMSN: A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning
比較手法のNABERT+:GitHub - raylin1000/drop-bert: NABERT model for solving the DROP dataset
評価用データセットDROPの論文:[1903.00161] DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
概要
- LanguageModelに数値推論を注入する汎用モデル(GenBERT)と、それをpre-trainingするための学習用データを生成するためのフレームワークを提案
- 既存の数値推論を評価用データセット(NRoT; Numerical Reasoning over Text)にてSOTAのモデルと同程度の性能を発揮することを示した
数値推論の例

数値推論の質問は複数種類あり、Passage(Contextともいう)やQuestionから該当する文字列を抽出すれば良いspanや、数値計算が必要なnumberがある。他にも複数のフレーズの抽出が必要なspansや、日付の計算が必要なdateがある。
提案手法の内容
複数のheadを用いて回答を行う。headの種類は3つ。
- answer type head: 回答方法を決定する(context span, question span, decodeのマルチクラス分類)
- two span-extraction heads: ContextかQuestionから回答を抽出する(NER)
- generative head: 回答を生成する

モデルのLossには以下を用いる。*1

EncoderのBERTとの差分
Digit Tokenization(DT)
数値計算用に数値を1文字ずつのwordpieceにする

Random Shift(RS)
“1086.1 - 2.54 + 343.8”の様な短いテキストを学習に用いるため、数値が先頭に来る場合に数値推論を行うようにオーバーフィットしてしまう。これを避けるためにposition IDをランダムにする*2。
学習・推論の全体像
pre-train済みのLanguageModel(BERT)をNumerical Data(ND)とTextual Data(TD)を用いて追加pre-trainする。
数値推論を行う場合はspan extraction headsとgenerative headの両方をfine-tuningする。 SQuADの様なテキストのみの質疑応答の場合はspan extraction headsのみを用いる。
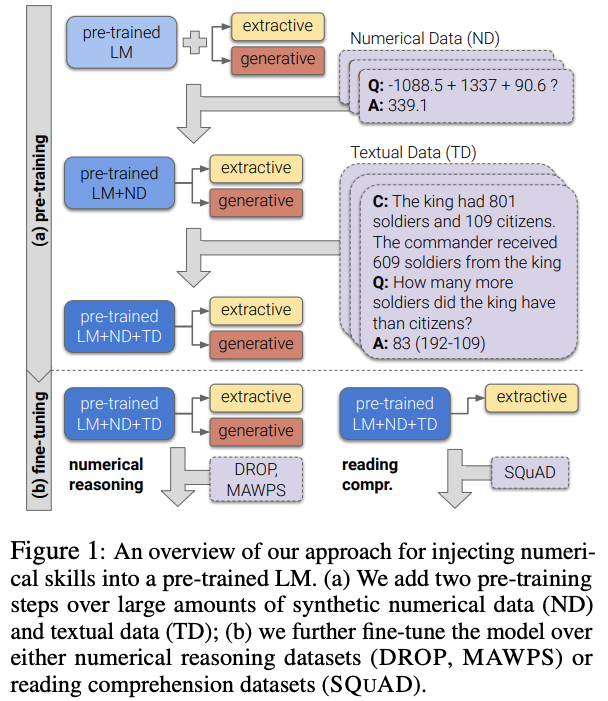
pre-trainingの方法
pre-training用のNumerical Data (ND)の生成
テンプレートを用いて数値演算のテキストを生成する。テンプレートはTable 2を参照。



数値実験
ND・TDによる追加pre-trainの効果
各モデルをDROPのデータでfine-tuningした結果で比較。追加pre-trainなしだとEMが46.1と低い。ND+TDで追加pre-trainすることでSOTAのMTMSNと同程度の性能になる*6。
Table 4からLM(追加pre-train時のMLM)やRandom Shiftも効果があることが分かる。

Digit Tokenizationの効果
pre-trainingのstep数毎のaccuracy。Digit Tokenizationが無い場合のみAccが低く、精度改善に寄与している事がわかる。

言語理解能力を失っていないかの確認
数値推論が不要な質疑応答(SQuAD)でfine-tuningして評価を行う。
GENBERTは数値推論を行いつつ、言語理解能力も失わずBERTと同程度であることが分かる。


補足
pre-training、fine-tuning時のパラメータ

DROPの質問種別毎の精度
数値計算(number)では予想通りMTMSNより精度が高い。
spanでもMTMSNより精度が高いが、これは内部的に数値計算を実行した上でspanを回答できるためだと考えられる。
spansは答えが連続しないフレーズのリストの質問だが、MTMSNはGENBERTを大幅に上回る。これはMTMSNはspans用の専用ヘッドを持っているが、GENBERTは標準的なReasoning Comprehension用のヘッドしか持たないためである。

数値理解能力の検証
数学の単語問題(MWP)データセットのコレクション(MAWPS)を用いて評価する。fine-tuningは行わずにzero-shotで評価を行う。
GENBERT+ND+TDは、GENBERT(BERTのママ)と比較して劇的に性能を向上させる。GENBERT+NDはGENBERT+TDよりもはるかに優れた性能を発揮し、コンテキストが短い場合のNDの有用性を示している。
MTMSNはGENBERT+ND+TDを上回る。MTMSNは足し算と引き算に特化したアーキテクチャを使用しており、モデル外で計算が行われる場合に適している。

次に、演算式の項の数で性能を比較する(図5)。図からすべてのモデルがより複雑な問題に一般化するのに苦労しており、項が4以上になると完全に失敗している。GENBERT+ND+TDの2項と3項の間の性能低下は、GENBERT+NDとGENBERT+TDよりも有意に小さい。このことはNDとTDの両方がロバスト性を向上させるのに有効であることを示唆している。

Error analysis
DROPのdevセットのGENBERT+ND+TDの誤答を分析する。モデルがサポートしていないマルチスパンの解答を持つ問題を除外した上で、GENBERT+ND+TDが誤答したものを100例のランダムサンプリングし、誤答の種類を手動で分類した。具体的な例は以下のTable 11を参照。

ほぼ半数のケース(43%)では、事前学習課題(ソートなど)でカバーされていないか、数値的ではない推論スキルを必要としているものだった。もう一つの一般的なケース(23%)は抽出したスパンが長すぎたり、予測値とgold answerと数字が部分的に一致する場合であった。これらのエラーの多くは、事前学習課題を拡張して追加の数値スキルやより大きな数値範囲をカバーすることで対処できると思われる。
*1:このLossだとspan extractionで抽出される文字列をdecoderで生成することも可能だが、span extractionで解くべき問題をdecoderで解いた場合にどういう計算になるのかは不明。またdecoderで解くべき問題の時に正しいspanを選択する確率がどうなるのか不明。
*2:Random Shiftで設定する値はwhen the input length n1 + n2 + 3 < 512, we shift all position IDs by a random integer in \(0, 1, . . . , 512 − \(n1 + n2 + 3\)
*3:Hosseini et al. 2014. Learning to Solve Arithmetic Word Problems with Verb Categorization - ACL Anthology
*4:データ生成は品詞に抽象化したテンプレートに単語を当てはめるような手法を用いている。Figure 3を参照。
*5:Kirkpatrick, 2017 [1612.00796] Overcoming catastrophic forgetting in neural networks
*6:SOTAはBERT-largeをベースにしたMTMSNだが、比較のために今回はBERT-baseをベースにしたMTMSNを比較対象としている
pythonのテストでmockを使う
pytest
固定値を返却させたい場合
mockerを使う場合はpytest-mockをインストールしておく必要がある
import numpy as np def get_rand(): return np.random.randint(0, 100) def test_random(mocker): mocker.patch("numpy.random.randint", return_value=55) assert get_rand() == 55
特定の値を順番に返却させたい場合
import numpy as np def get_rand(): return np.random.randint(0, 100) def test_random(mocker): mocker.patch("numpy.random.randint", side_effect=[5, 55, 999]) assert get_rand() == 5 assert get_rand() == 55 assert get_rand() == 999
BERT-based similarity learning for product matchingを読んだ
概要
COLING2020に採択
BERT-based similarity learning for product matching - ACL Anthology
著者
- Janusz Tracz (ML Research at Allegro.pl)
- Piotr Wojcik (ML Research at Allegro.pl)
- Kalina Jasinska-Kobus (ML Research at Allegro.pl, Poznan University of Technology)
- Riccardo Belluzzo (ML Research at Allegro.pl)
- Robert Mroczkowski (ML Research at Allegro.pl)
- Ireneusz Gawlik (ML Research at Allegro.pl, AGH University of Science and Technology)
contributions
- BERTを用いたsimilarity learningをECドメインでの製品マッチングに適用した
- BERTとDistil BERTを製品マッチングに適用した場合の有用性を比較した
- 提案したcategory hardはsimilarity learning時のthe fraction of active training tripletsを増やし、モデルの性能を向上させた
- category hardも含めたbatch construction strategiesの比較を行った
問題設定
製品と商品のマッチングを行う。製品はカタログでマスタのようなもの。商品は売り手が出しているもの(論文中ではofferと書かれている)。
本論文ではテキスト情報を元に、商品がどの製品に該当するのか特定する(マッチングする)ことを目的としている。
提案手法
Encoder
入力とするテキストはtitle, attributes values, attribute unitsを結合したもの。
テキストは小文字化し、byte-pair encoderで分割する。tokenizerは商品・製品データのコーパスで学習し、ボキャブラリーサイズは30k tokensとした。
descriptionやattribute namesを含めたテストも行ったが、全ての実験で性能が劣化した。
EncoderにはBERTの最終層をmean poolingした後に768 linear unitsを1層追加したものを用いる。これをeComBERTと呼ぶ。
学習方法
triplet lossを用いてsimilarity learningを行う。
tripletをとし、それぞれoffer(anchor)、matching product(positive)、non-matching product(negative)とする。
商品(offer)のEncoderを 、製品のEncoderを
とする。
と
はパラメータを共有する。
Lossは以下とする。
はマージンでハイパーパラメータ。
は距離関数でcosine距離を用いる。
Batch construction strategy
アンカー(商品)とpositive(製品)のペアは商品と製品の一致データからサンプリングして作成する。negative productは自明ではないので工夫する必要がある。
以下の3つの方法を検証する。本論文で新規に提案するのはcategory hard。
- category random
- batch hard
- category hard
category random
商品と一致しない製品の中から同一カテゴリの製品をランダムに選択しnegativeとする。
バッチについては言及されていないので、全データの同一カテゴリからランダム選択と思われる。
batch hard
アンカー(商品)とpositive(製品)のペアのバッチを作成し、バッチ内でアンカーと一致しない製品かつ最も似ている製品をnegativeとする。この手法の場合、バッチサイズが大きいほど似ている製品が見つかりやすいので、バッチサイズが性能に大きく影響する。
negativeを選択する際に最も似ているものを選ぶとあるが、似ている基準については言及されていない。
category hard
商品と一致しない、かつ同一カテゴリの製品の中で最も商品に似ている製品をnegativeとする。そのために全製品のembeddingが必要になると記載されているので、似ているかどうかはcosine距離を基準にすると思われる。全製品のembedding算出は処理時間がかかるため、100ステップや500ステップなど一定の間隔で再計算を行う。
実験
データセット
3カテゴリのデータセットを評価に用いる。実世界のECで適切に処理されたとだけ記載されており、手作業でクレンジングしたかどうかは不明。
評価時に商品はencoderから得られた分散表現ベクトルのcos距離が最も近い製品とマッチングを行うとあるので、商品は必ず製品に属していると考えられる。特に記載は無いが、CULTUREとELECTRONICSはProductsの方が多いので、商品が紐付いていない製品が存在すると思われる。

データセットを学習:80%、テスト:20%に分割して用いる。ただし、zero-shotの評価のために製品の半分はテストデータセットにしか存在しないようにする。
データセット毎にencoderを学習。学習時の設定は5000steps、バッチサイズ32、Adam optimizer with initial learning rate 2 · 10−5。
ハイパーパラメータのマージンについての記載は無し。
他手法との比較
StartSpaceというBoW encoderと、HerBERTと比較。eComBERTが提案手法。HerBERTはRoBERTaのfashionコーパスでBERTをpretrainしたもの。HerBERTのauthorと本論文のauthorは数名重複している。
BEAUTYはHerBERTとeComBERTのfine-tunedされたものとそれ以外ではaccuracyにかなり違いがあるが、BEAUTYは製品数が少ないため、商品がどの製品に紐づくかどうかがCULTURE、ELECTRONICSに比べて難しいのかもしれない。

non-finetunedではencoderのweightの追加学習を行っていないが、BERTの最終層のmean poolingしたものをembeddingとして使う。
pretrainingのステップ数によるパフォーマンスの変化
標準的なBERTのpretrainingは数十万ステップ行われるが、提案手法で名寄せを行う場合はpretrainingに必要なステップ数はもっと少なくても十分な性能が出る。参考までにNICTのBERTのモデルは合計110万ステップ。
Figure1はpretrainingのステップ数に対するMLMとBEAUTYのテストデータセットに対するaccuracy。左図と右図の横軸は共有されている。pretrainingのステップ数が2万ステップを超えたあたりでテストデータセットの精度はあまり変化しないので、数十万ステップを行わなくても十分な精度が得られる。名寄せに関してはpretrainingの効果が頭打ちになりやすいとも言えそう。

triplet作成方法毎の性能の違い
tripletを作成する3つの手法のcategory random(CR)、batch hard(BH)、category hard(CH)の性能を比較。
fraction of active tripletsの意味がよく分からないが、Figure 2ではfraction of active tripletsは0から1の範囲なのでnegative productsを選択できてtripletを作成できた比率を指していると思われる。また、lossが負になるtripletも除外されているかもしれない。
Figure 2 (a)はHerBERTのfine-tuneの最初の方のステップのfraction of active tripletsを示したもの。batch hardとcategory randomは50ステップあたりでactive tripletsの数が平坦になり、学習に使えるtripletが少なくなって学習の効率が落ちる。これに対してcategory hardはactive tripletsの数が最初から多く、距離を再計算する100ステップ目でactive triplets数が急激に回復している。著者によると100ステップ目移行は距離の再計算をしても同様の急激なactive tripletsの変化は起きず収束し始めていたとのこと。
Figure2 (b)はcategory hardをHerBERTと提案手法のeComBERTに適用した場合の比較。最初の方はeComBERTの方が初期ステップではactive tripletsがHerBERTより多く、途中からHerBERTより少なくなるのでeComBERTは学習初期に製品と商品の類似性を学習できているのではと述べられている。

1000ステップのときのtest accuracy。収束はしてないが、1000ステップが最も精度が良かったらしい(なぜTable 1の結果を1000ステップにしなかったのは謎である)
HerBERTとeComBERTに各batch strategyを適用した場合の比較。
eComBERTの方がHerBERTより性能が良くなる。

Encoderのlayer数を減らしたりDistilした場合の精度と処理時間
small eComBERT(eComBERTを4層にしたもの)とDistil eComBERTを用意。
精度はTable 4に示す通り。ほとんど差は無い。
推論時間はeComBERTに対してDistil eComBERTは半分、small eComBERTは2/3になったとのこと。


はてなブログを書くときのメモ
公式:はてなブログ ヘルプ
記法
上付き、下付き
<sup> 上付きにしたい文字 </sup>
<sub> 上付きにしたい文字 </sub>
コードブロック
>|言語名|
ソースコード
||<
インラインコード
<code> と</code>で挟む
画像
画像の貼り付け
- 画像をコピペしてアップロードする
- はてな記法で貼り付けたい場合は、右側のサイドバーの「写真を投稿」で画像を選び、「選択した写真を貼り付け」で貼る
サイズの指定
横幅の指定
[f:id:wwacky:20201209041958p:plain:w300]
高さの指定
[f:id:wwacky:20201209041958p:plain:h200]
キャプションの設定
貼付け時にキャプションを書いて貼る
Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Productを読む
概要
ECの商品情報のテキストに含まれるAttributeとその値の抽出を行う。テキストの系列ラベリングだけでなくAttributeのクラス分類と同時学習させ、素性にはテキストと画像を用いたマルチモーダルにしつつも画像からのノイズをフィルタリングするためのGateを含めたArchitectureを提案。
EMNLP2020で採択
[2009.07162] Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product
著者
- Tiangang Zhu (JD AI Research)
- Yue Wang (JD AI Research)
- Haoran Li (JD AI Research)
- Youzheng Wu (JD AI Research)
- Xiaodong He (JD AI Research)
- Bowen Zhou (JD AI Research)
問題設定
商品名や商品詳細のようなテキストに対して商品特徴のNERを行う。商品特徴は「色」「襟の種類」など。 提案手法ではNERを行う際に画像特徴量も用いる。
Figure 1の例では「This golden lapel shirt can be dressed up with black shoes...」というテキストがある時に"golden"は色かもしれないし素材かもしれないが画像から"golden"は色だと分かるし、"black"という単語は画像を見れば対象商品に対するものではないので抽出しないということが可能になる。
(goldenが素材かもしれないというのがよく分からないが、アクセサリーなどで素材が金といったことを指しているのでは無いかと思われる)

contribution
提案手法
提案手法では以下の2つのタスクを解く。
- Product Attribute Prediction (sequence-level multi-label classification)
- Product Value Extraction (sequence labeling task)
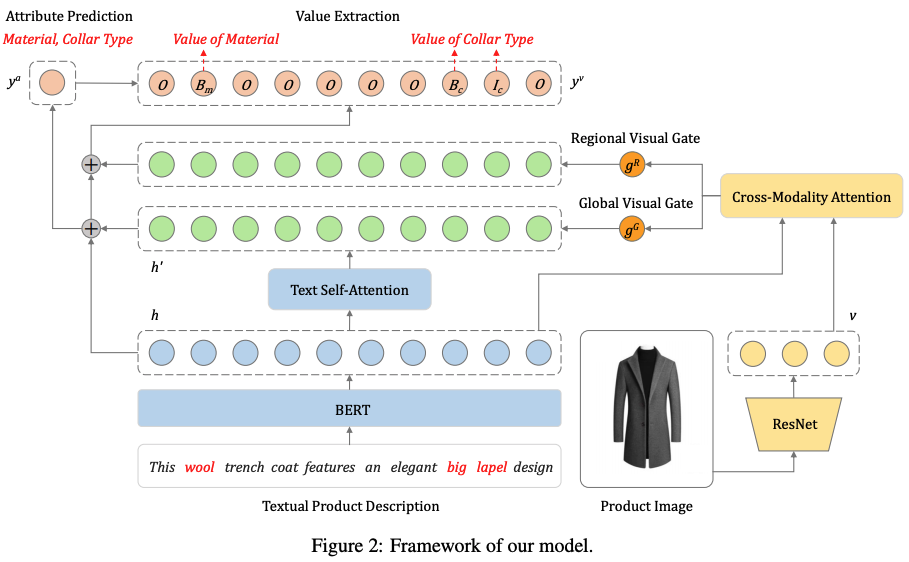
Encoder
Text Encoder
BERTを使う。
Image Encoder
ResNetを使用。global visual featureとregional image featureの2つを用いる。
- global visual feature
: 最終Pooling層の出力を用いる。
- regional image feature
:ResNetのconv5の7 x 7 x 2048 の特徴量を用いる。K=49。(恐らく位置情報は考慮せずに49個=7x7の2048次元のベクトルとして扱う)
Product Attention Prediction
画像がテキストの意味を表現できない場合に画像情報がノイズとならない様に、Gateを設置する。

式(5)の第1項はtoken-tokenのAttention。はBERTの出力。
式(5)の第2項はtoken-image regionのAttention。
GateのはBERTの出力
と画像全体の特徴量
に依存する。

token-tokenとtoken-image regionのattentionをかけた、BERTの出力
、BERTの[CLS]トークンの出力
を用いてマルチラベル分類を行う。
が正解のAttributeを表しており、Attributeを持つときは1が立つ。Attributeは全部でL個。

Lossはクロスエントロピーを用いる。


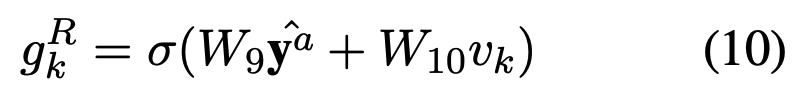



実験
データセット
中国のEC(https://www.jd.com/)から取得したデータセットを用いる。ラベルはクラウドソーシングで作成。

既存手法との比較
提案手法はM-JAVE(Multimodal Joint Attribute prediction and Value Extraction)。
JAVEは提案手法からGateを外して画像特徴量を入れずにテキスト情報だけでタスクを解くモデル。

既存手法は恐らく全てtextのみを使った手法。そのため、既存手法との比較はJAVEと行った方が良い。既存手法に比べて若干JAVEの方がF1スコアが高いが、そこまで大きな差はない。
M-JAVEにするとF1スコアが3ポイントほど上昇するので、この3ポイントが画像の効果と思われる。
カテゴリ毎のAttribute PredictionとValue ExtractionのF1スコア
カテゴリ毎にほとんど差はない。(論文中に対して考察は書いてない。たぶん)

Attribute毎のAttribute PredictionとValue ExtractionのF1スコア
(論文中に対して考察は書いてない。たぶん)
F1が高いAttribute:Shape, Pant Length, Neckline Depth, Slit Type, Elasticity(弾性)
F1が低いAttribute:Pocket Type, Thickness
テキストだけで当てられる、画像が無いと当てるのが難しいといった違いは見られない。人間が見ても判断が難しいどうかが影響している気もするが不明。Pant LengthのF1は高いが、Sleeve LengthやSkirt LengthのF1が低いのは気になるが、特に理由は書いてなかった。

Ablation Study
テキストだけのJAVEに対してAblation Studyを行う。
- w/o MTL:MultiTaskLearningを行わない(具体的にどう学習させるかは書いてない)
- w/o AttrPred:Value Extractionを行う際にAttribute Predictionの結果を使わない(式9の
を除外する)
- w/o KL-Loss:学習時のKL-Lossを外す(式14の
を0にする)
- UpBound of Attribute Task:Value Extractionが全て正解だった場合のAttribute PredictionのF1
- UpBound of Value Task:Attribute Predictionが全て正解だった場合のValue ExtractionのF1
元々の問題設定としてはValue Extractionだけ解けばよいのだが、Attribute Predictionがあることで若干だが精度が上がっている事がわかる。また、UpBoundのパターンでは片方の精度が上がればもう片方も上がることが示されているので、互いに相関関係にあるといえる。

画像特徴量も含めたM-JAVEのAblation Studyを行う。
- w/o Visual Info:JAVEと同じ状態
- w/o Global-Gated CrossMAtt:global-gated cross-modality attentionを除外する(式5の右辺を除外。画像全体の特徴量が加算されなくなる)
- w/o Regional-Gated CrossMAtt:regional-gated cross-modality attentionを除外する(式9の一番右の項を除外。画像のregion毎の畳み込み特徴量が加算されなくなる)
- w/o Global Visual Gate:global visual gateを除外する(式5の
を除外する。gateの値は除外するが、画像全体のcross-modality attentionはそのまま加算される)
- w/o Regional Visual Gate:regional visual gateを除外する(式9の
を除外する。gateの値は除外するが、画像Region毎のcross-modality attentionはそのまま加算される)
Gateが無い場合のF1スコアの下がり幅が最も大きく、テキストのみのJAVEよりもF1スコアが低くなってしまう。即ち画像特徴量をAttention込みで組み込んでも精度が上がらず、画像特徴量を用いて精度を上げるためにはGateを用いたフィルタリングが有効であることが示されている。
一方でcross-modality attentionを除外すると画像の全体かregion毎のどちらかが考慮されなくなるが、テキストのみのJAVEよりはF1スコアが高くなる。

Low-Resource Evaluation
ランダムサンプリングで学習データの量を減らした場合のF1スコアを評価。学習データが少なくなるとJAVEとM-JAVEの差が大きくなり、学習データが少ない時ほど画像の効果があることが分かる。
